A System Can Be Technically Working and Still Be Failing Its Users
I spent some time thinking about a simple scenario:
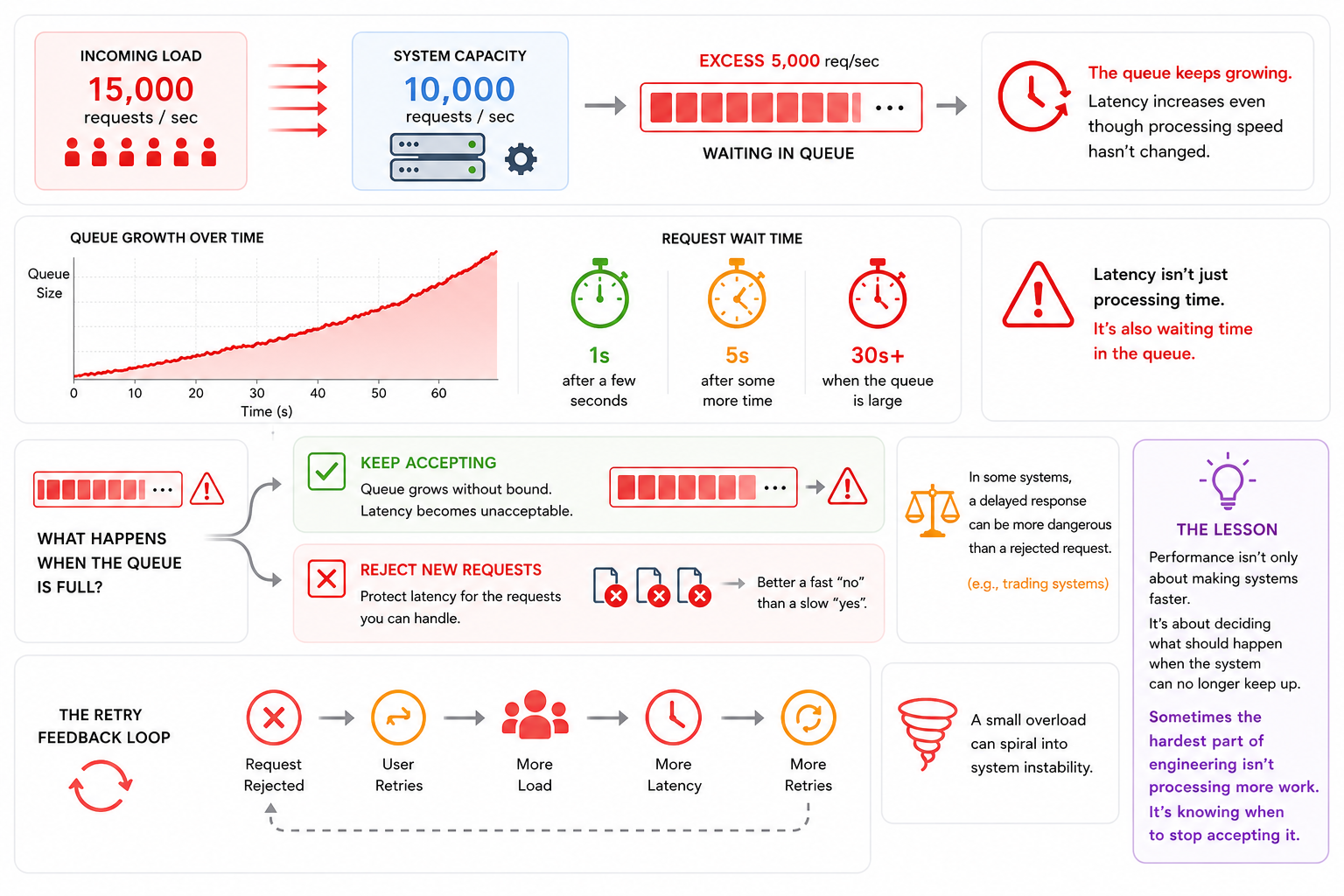
A system can process 10,000 requests per second, but suddenly receives 15,000 requests per second.
My first thought was straightforward:
The extra 5,000 requests can just wait in a queue until the system catches up sounds reasonable.
But then I started following the consequences.
If 5,000 extra requests arrive every second, the queue keeps growing.
After a few seconds, requests are no longer waiting for milliseconds. They're waiting for seconds.
Now latency starts increasing even though the processing speed of the system hasn't changed at all.
That led me to another realization:
Latency isn't only about how long a system spends processing a request.
It's also about how long a request spends waiting before it gets processed.
Then things get more interesting.
What happens when the queue becomes full?
One option is to keep accepting everything and let the queue grow.
Another option is to reject new requests and keep latency under control.
My initial instinct was to accept everything.
But the more I thought about it, the more I realized that in some systems, especially trading systems, a delayed response can be more dangerous than a rejected request.
An order that executes 30 seconds later may be based on a completely different market than the one the user intended to trade.
Then I explored another problem.
What happens when users start retrying?
A rejected request creates more requests.
More requests create more load.
More load creates more latency.
More latency creates more retries.
A small overload can turn into a feedback loop that makes the entire system unstable.
The lesson I took away from today,
Performance isn't only about making systems faster.
It's also about deciding what should happen when the system can no longer keep up.
Sometimes the hardest part of engineering isn't processing more work.
It's knowing when to stop accepting it.